
容芯致远石旭:智算时代呼唤以GPU为核心的AI体系结构
21世纪经济报道记者孙燕 苏州报道
自2023年ChatGPT引爆生成式AI革命以来,智算需求呈爆炸式增长。进入2025年,随着大量AI应用上线,高端GPU“一卡难求”,算力愈发成为核心生产资料。
“除非量子计算、光子计算能够大规模替代硅基计算,否则后摩尔时代一定是体系结构的天下。”11月14日,容芯致远联合创始人、CTO石旭在21世纪卓越董事会(苏州站)活动上表示。
图片来源于网络,如有侵权,请联系删除
在石旭看来,单纯依靠提升芯片制程来提高芯片性能、进而优化计算机系统性能的路径已走到尽头,只有算力芯片、交换芯片、软件生态协同更新,才能实现计算机系统的性能迭代。“因此英伟达不仅做算力芯片(GPU),还做网络芯片(收购Mellanox)、交换芯片(NVSwitch)以及软件生态(CUDA)。”

从通算到智算
据统计,2023年中国通算服务器销量为470万台,智算服务器销量为15万台。而到了2025年上半年,通算服务器销量萎缩到100多万台,智算服务器销量则攀升至100多万台。
业内普遍认为,这一转变的关键点在于Deepseek混合专家模型(MoE)架构的诞生:在GPT-3等传统的稠密模型下,输入任何问题都要激活模型中的全部参数;MoE模型内包含多个子模型,可以“按需激活”,直接降低了大模型训练和推理的单位成本。
石旭认为,类似于英特尔X86颠覆了大型机、小型机,使得计算机能够进行企业、家庭,带来了互联网、云计算、大数据的发展;Deepseek的MoE架构使得智算进入企业、家庭成为现实。
这为国产GPU提供了一个“弯道超车”机遇:它不要求某一个GPU单元拥有极高的单卡性能,而追求GPU的数量多,因此更考验多卡协同工作的效率。
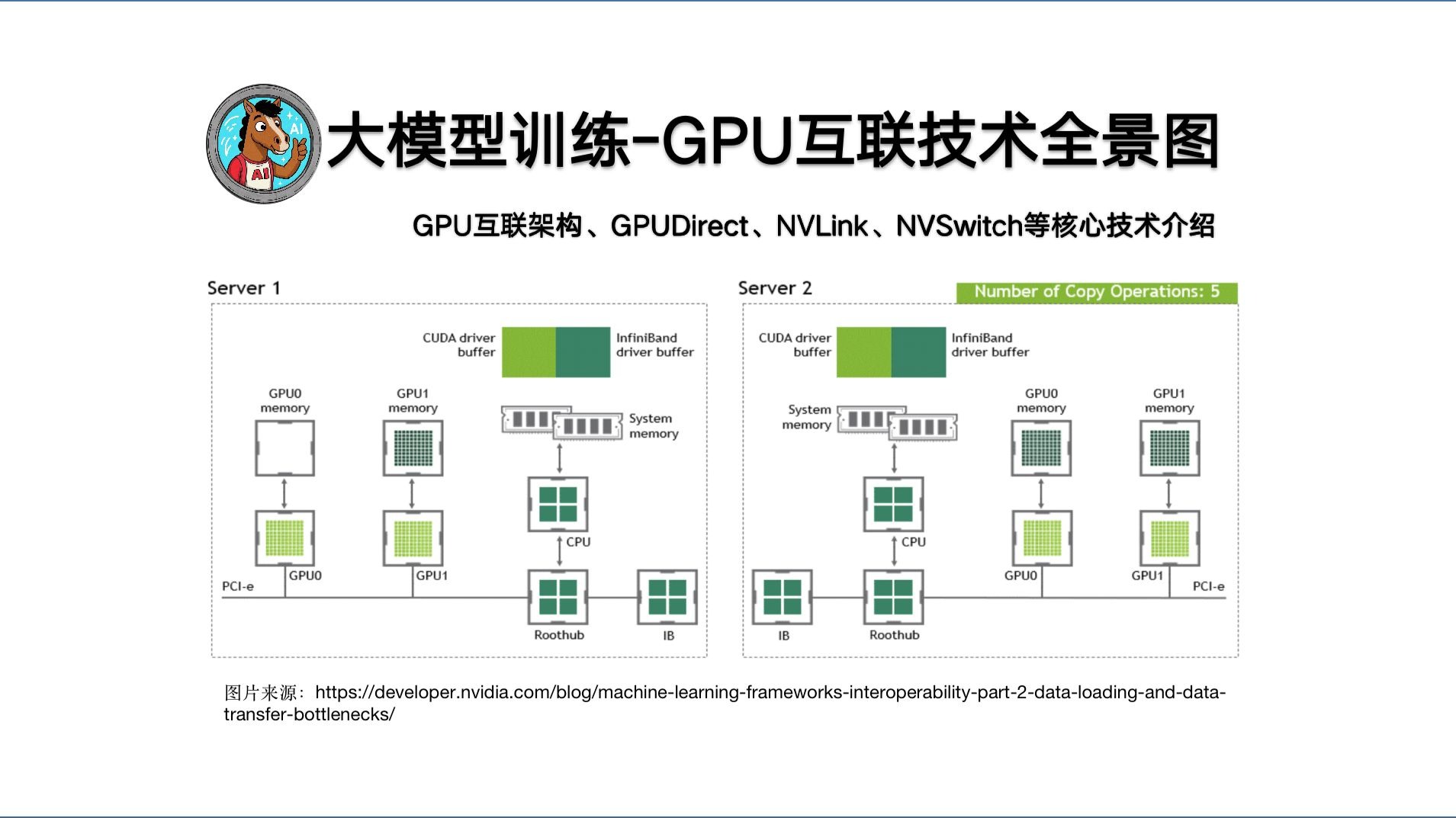
但当前,多卡协同工作依然存在不少通信瓶颈。
石旭告诉21世纪经济报道记者,传统铜互连的高速互联方式,只能提供几十厘米级的低延迟互联能力。这不仅使得在设备内部构建8卡甚至更多GPU设备变得愈发困难,而且也对高功耗的散热设计提出了挑战。
面对传统铜互联的物理瓶颈,业界已达成共识,要构建“电算光传”的下一代数据中心架构:用电计算,用光传输,从而让计算回归芯片、让传输走向光纤。
石旭指出,由于激光光源的基础原理是受激辐射,功率密度高,需要工作在相对比较低的环境温度中,最佳工作温度是小于60℃的环境温度。因此只能解决服务器之间高速互联的问题,仍然无法解决服务器内部芯片间高速互联的问题。“英伟达也在研发类似的技术。我们首创了不受60℃限制的光传输技术(BlueLink),所以能做出配备20张GPU卡的服务器,1台即可高效运行671B满血版大模型。”
以GPU为中心
在智算行业,算力技术与算法模型构成了两大支柱:算法模型以AI大模型为代表持续突破,算力技术则通过AI芯片、AI服务器及集群等硬件载体实现支撑。
近年来,随着摩尔定律放缓,CPU受到制程限制,正在接近极限。面对“不堪重负”的CPU,以英特尔为代表的厂商自2019年推动“基础设施处理单元”(IPU),以英伟达为代表的厂商则推出了“数据处理单元”(DPU),以接管“杂务”、减轻CPU的负担。
但CPU“串行处理”的架构并不适合AI、大数据等大规模并行计算任务。而原本为游戏图像渲染而设计的GPU,其多核、高速、高并行等性能远远超过CPU,逐渐成为AI时代不可或缺的算力核心。
然而,在传统的以CPU为中心的传统AI架构(AI computer system with the CPU as its Core,简称ACC)中,GPU仅作为PCIe总线上的协处理器存在,其地位、形态都类似于外设的硬盘、网卡,强大性能无法被充分释放。
为了打破这一枷锁,业界正转向以GPU和数据为中心的全新架构,以解放GPU的算力潜能,如英伟达提出了GPU硬件架构以及配套的CUDA软件平台、容芯致远提出了AGC(AI computer system with the GPU as its Core)智算架构。
石旭指出,在GPU为核心的AGC智算架构中,CPU成了“外设”。这降低了对于CPU的性能要求,英特尔、AMD的CPU不再是必需,国产CPU也能支持国产GPU较好发挥性能。
要以GPU为中心,还要解决GPU高故障率、高耗能、寿命短等应用痛点。
石旭指出,AIDC(智算中心)的故障率约为20%-30%。这是因为,GPU凭借先进制程实现了超高晶体管密度,但也因此对温度极为敏感,高温极易引发性能衰减乃至任务中断。尤其在数据中心7x24小时满负荷运行的极限工况下,其经济寿命可能被压缩至短短2-3年。为此,容芯致远率先突破了GPU热插拔、GPU RAID高可用和GPU节能延寿技术,让GPU从脆弱、昂贵的奢侈品转变为可靠、经济的生产力工具。
通过AI架构创新,也能够将算力有效值(MFU)从传统服务器的平均40%提升至60%以上。石旭指出,虽然英伟达的GPU标称算力值高,但在国产GPU算力逊于英伟达的情况下,提高MFU也能够提高算力值。“这就是体系的力量。”







